

дівцНсЙЙЕїећЕФФПЕФЪЧЪЙИїМЖЩшБИЃЈШчвєЦЕДІРэЦїЃЉЛёЕУзюДѓаХдыБШЃЌВЂЪЙвєЦЕЯЕЭГВйзїепЛёЕУИќДѓЕФЕїНкПеМфгыВйзїАВШЋадЁЃБОЮФНЋвдЩшжУвєЦЕДІРэЦїдівцНсЙЙЮЊЧаШыЕуЃЌДгдРэНтЮіЁЂЪЕВйВНжшвдМАГЃМћЮЪЬтЗжЮіЃЌШУФуеЦЮедРэНјЖјПЩвдЪЪгУгкећИівєЦЕЯЕЭГЕФЕїећЁЃ
зїЮЊБЛЩшМЦдкБъГЦВйзїЕчЦНЩЯЪЙгУЕФвєЦЕЩшБИЃЌЖдЭЈЙ§ЕФаХКХгазХЩЯЯожЕЕФвЊЧѓЃЌвЛЕЉаХКХГЌЙ§ЩЯЯожЕОЭЛсЗЂЩњЯїВЈЪЇецЁЃЭЌбљЃЌЫљгаЕФЩшБИвВгааХКХЕФЯТЯожЕМДБОЕздыЩљЃЌгааЇаХКХШєЕЭгкБОЕздыЩљдђЛсБЛдыЩљбЭУЛЁЃ
Ј
ЖЏЬЌЗЖЮЇ
ЕБаХКХдквєЦЕЩшБИЭЈЕРжаДЋЪфЪБЃЌЮвУЧБиаыЭЌЪБЙизЂЩшБИЕФзюДѓЪфШыЕчЦНгыБОЕздыЩљЫЎЦНЃЌетСНепжЎМфЕФБШжЕЮвУЧГЦЮЊИУЩшБИЕФЖЏЬЌЗЖЮЇЁЃЃЈЧјБ№гкЮвУЧГЃГЃЬИТлЕФвєЦЕаХКХЖЏЬЌЗЖЮЇЃЌШчНЛЯьРжгЕгаБШаТЮХВЅБЈИќДѓЕФЖЏЬЌЗЖЮЇжИЕФОЭЪЧаХКХЖЏЬЌЗЖЮЇЁЃЃЉ

ЖЏЬЌЗЖЮЇЁЂаХдыБШгыЗхжЕПеМфЕФЙиЯЕ
Г§СЫЙизЂФЃФтЦїМўЕФжИБъЃЌЖдгкЪ§зжЩшБИЖјбдЃЌвєЦЕаХКХВЩбљСПЛЏЕФЮЛЩю(bit)вВОіЖЈСЫЩшБИЕФЖЏЬЌЁЃЭЈЙ§вд1-bitЮЊ6dBЕФЖЏЬЌжЕМЦЫуЃЌ16bitзюДѓЖЏЬЌЮЊ16x6=96dBЃЌ24bitЕФЩшБИдђПЩвдгЕга24x6=144dBЕФЖЏЬЌЁЃвВОЭЪЧЫЕЃЌВЩбљЮЛЩюЪ§жЕдНДѓЃЌЩшБИЖЏЬЌЗЖЮЇОЭдНДѓЁЃетРяЧыЮ№гыФЃФтаХКХЕФЖЏЬЌЗЖЮЇЛьЯ§ЁЃ
Ј
БОЕздыЩљ
ЕБзюаЁЕФвєЦЕаХКХЕЭгкБОЕздыЩљЫЎЦНЪБЃЌгявєПЩЖЎЖШЛсЪмЕНдыЩљгАЯьЖјНЕЕЭЁЃЪТЪЕЩЯЃЌЕБвєЦЕаХКХЕчЦНжЛгыБОЕздыЩљЫЎЦНЯрВюЮоМИЪБЃЌШЫЖњЬ§ИаЖдетбљЕФЩљвєвВЪЧВЛФмШЬЪмЕФЁЃЖдвєЦЕЯЕЭГаХдыБШЕФвЊЧѓОпЬхШЁОігкВЛЭЌгІгУГЁОАЃЌЕЋзмЕФРДЫЕЃЌдНЪЧзЈвЕРЉЩљЕФГЁКЯОЭдНЪЧгІЕБЖдаХдыБШЬсГіИпЕФвЊЧѓЁЃ
Ј
ЯїВЈЪЇец
МйШчЪфШыаХКХЕчЦНГЌЙ§СЫЩшБИЕФзюДѓЕчЦНЃЌЩшБИЛсГіЯжЯїВЈЪЇецЁЃОйР§ЩшБИЕФзюДѓЪфШыЕчЦНЮЊ+20dBuЃЌШчЙћИјЫќЪфШывЛИіЗхжЕЕчЦНДяЕН+24dBuЕФаХКХЃЌаХКХНЋЛсВњЩњЯїВЈЪЇецЁЃдкЪЕМЪгІгУЕБжаЃЌЮвУЧЯЃЭћБмУтаХКХЯїВЈЕФСэвЛИіживЊдвђЪЧЃКЕБЯїВЈЗЂЩњЪБЃЌЦфЫљВњЩњЕФжБСїГЩЗжЖдбяЩљЦїЕФЯпШІгазХжТУќадЕФДнЛйзїгУЃЌЖЬЖЬЪ§УыФкОЭПЩФмНЋбяЩљЦїРяИпЦЕЕЅдЊЩеЛйЁЃ
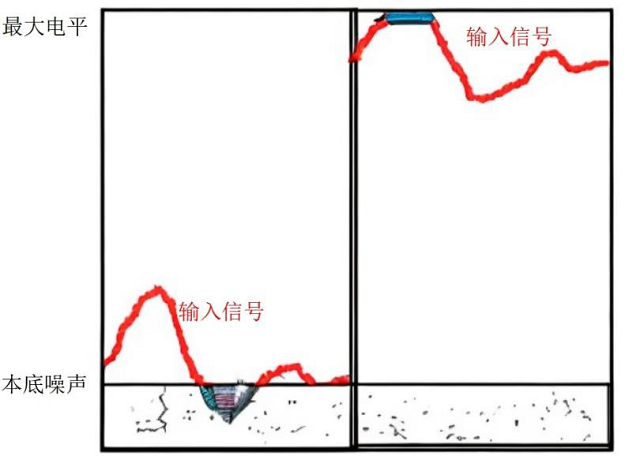
ЭМзѓЃКаХКХБЛЩшБИБОЕздыЩљбЭУЛЃЛЭМгвЃКаХКХЗЂЩњЯїВЈЪЇец
Ј
дівцНсЙЙ
МШШЛвєЦЕЯЕЭГдкЕЅИівєЦЕЩшБИжаДЋЪфвЊПМТЧЖЏЬЌЗЖЮЇЃЌФЧУДзїЮЊгЩИїИівєЦЕЩшБИЫљзщГЩЕФвєЦЕЯЕЭГздШЛвВгаЯЕЭГЕФЖЏЬЌЗЖЮЇЁЃвєЦЕЯЕЭГЕФЖЏЬЌЗЖЮЇКмДѓГЬЖШЩЯвРРЕгкЯЕЭГЙЄГЬЪІЖдЩшБИЕФбЁаЭвдМАЁАдівцНсЙЙЁБЕФХфжУЁЃЖјетвЛЕуЗћКЯЁАФОЭАЖЬАхаЇгІЁБЃЌШчдкзЈвЕвєЦЕЯЕЭГжаВхШыЯћЗбМЖЕФЩшБИВЛЪЧУїжЧЕФбЁдёЁЃМДЪЙВЩгУЕФЖМЪЧзЈвЕМЖБ№ЕФЩшБИЃЌвВгаПЩФмвђЮЊдівцЩшжУВЛЕУЕБЖјДяВЛЕНЯЕЭГЦкЭћЕФЪЙгУаЇЙћЁЃ
ФЧУДЃЌЪВУДЪЧЁАдівцНсЙЙЁБФиЃПдівцНсЙЙЃЈgain structureЃЉПЩвдЖЈвхЮЊЗЂЩњдквєЦЕаХКХСДТЗЕБжаЕФИїМЖдівцЙиЯЕЃЌШчдквєдДгывєЦЕДІРэЦїжЎМфЁЂвєЦЕДІРэЦїгыЙІЗХжЎМфЕШЕШЁЃ
вЛжжВЛе§ШЗЕФдівцНсЙЙЩшжУПЩФмЛсЕМжТЃК
змЖјбджЎЃЌЮвУЧОЁПЩФмЕиЯЃЭћвєЦЕдЫаадкЖЏЬЌЗЖЮЇзюДѓЛЏЃЈЧваХдыБШзюДѓЛЏЃЉЕФЯЕЭГЕБжаЃЌвде§ШЗжиЯжШЫЩљЛђНкФПвєЦЕЕФИќЖрЯИНкЁЃ
еЦЮеСЫЩЯУцЕФБГОАжЊЪЖЃЌвдЯТВНжшНЋФмжИв§ФудкЪЕМЪЪЙгУЕБжаЭъГЩЖдвєЦЕДІРэЦїЕФдівцНсЙЙЩшжУЁЃ
ЫФВНИуЖЈдівцНсЙЙЕїећ
ЃЈ1ЃЉЙиБеФуЕФЙІЗХ
вЊЩшжУе§ШЗЕФдівцНсЙЙвЊЧѓЮвУЧгЩаХКХСДТЗДгЧАЭљКѓРДНјааЕїећЃЌдкетвЛВНжшжаЃЌФуВЛашвЊЬ§ЕНШЮКЮЩљвєЃЌжЛашвЊВЮПМЕчЦНМДПЩЁЃ
ЃЈ2ЃЉЕїећвєдДЕФЪфГіЮЛжУ
ФуЛђаэЛсдкФГаЉвєдДЩшБИЩЯЗЂЯжВЛжЙвЛжжРраЭЕФвєЦЕЪфГіНгПкЃЌЛђЪЧОпгаMic/LineЕчЦНбЁдёЕФВІЕЕЃЈШчЮоЯпЛАЭВНгЪеЛњЃЉЁЃ

ЮоЯпЛАЭВНгЪеЛњВЛЭЌРраЭЕФвєЦЕЪфГі
ЪзЯШЃЌдкзЈвЕвєЦЕЯЕЭГСЌНгжаЃЌЮвУЧОЁПЩФмЕиЪЙгУЦНКтНгПкНјааСЌНгЃЌетбљФмЙЛНјааГЄОрРыЕиДЋЪфЖјВЛЖюЭтв§ШыИќЖрдыЩљЁЃ
ШчЙћЪЧашвЊНЋвєдДСЌНгЕНвЛАуЕФДЋЭГЕївєЬЈЃЌЛЙашвЊзЂвтНгПкРраЭжЎМфДцдкВювьЃЌашвЊНсКЯВщПДВњЦЗЙцИёЪщЁЃШчгУгкMicЕчЦНСЌНгЕФПЈйЏНгПкЃЈXLRЃЉЫљФмГаЪмЕФзюДѓЪфШыЕчЦНБШгУгкLineЕчЦНСЌНгЕФДѓШ§аОНгПкЃЈTRSЃЉЕФЕЭЁЃ
ЖјЖдгкНЋвєдДСЌНгЕНЮвУЧЕФвєЦЕДІРэЦїЩЯдђЮоДЫЙЫТЧЃЌУПИіЪфШыЭЈЕРЕФНгПкЪЪгУгкЮоТлЪЧMicЕчЦНЛђЪЧLineЕчЦНЕФвєдДЃЌЭЌЪБОпгаПЩЖРСЂПижЦЕФ48VЛУЯѓЙЉЕчПЊЙиКЭВННјСщУєЖШдівцЃЈЛАЗХЃЉЕїНкЃЌПЩзїЮЊЛАЭВЧАМЖЖдЛАЗХдівцНјааОЋЯИЩшжУЁЃЃЈЩшжУЗНЗЈдкЕкЂлВНжшНјааЯъЯИВћЪіЁЃЃЉ
СэЭтЃЌШчЙћЪЧНкФПдДРраЭЕФвєдДЃЈШчВЅЗХЦїЃЉЃЌЦфЭЈГЃОпгаКуЖЈЕФБОЕздыЩљЁЃЭЈЙ§діМгвєдДздЩэЕФЪфГіЕчЦНОЭФмдіМгаХдыБШЃЌПЩвддкНјШыЕНДІРэЦїВЛЪЇецЕФЧАЬсЯТОЁСПЕїИпЁЃ
ЃЈ3ЃЉЕїећвєЦЕДІРэЦїЪфШыСщУєЖШдівцЃЈЛАЗХЃЉ
ЖдгкЕївєЬЈЛђЪ§зжвєЦЕДІРэЦїЩшБИЖјбдЃЌЦфБОЩэвВОпгаКуЖЈЕФБОЕздыЩљЁЃ
ЖдгкLineЕчЦННгШыЕФЪфШыаХКХЃЌвЛАуЮоашЕїећЪфШыСщУєЖШдівцЃЈЛАЗХЃЉОЭПЩвдгЕгазуЙЛЕФаХдыБШЁЃЕЋЪЧШчЙћЖдгкMicЕчЦНЛђЯћЗбРрвєЦЕВњЦЗНгШыЃЌдђВЛПЩБмУтГіЯжаХдыБШВЛзуЕФЧщПіЁЃвђДЫашвЊдкаХКХНјШыADCФЃЪ§зЊЛЛжЎЧАЃЈМДдкВЛдіМгЩшБИздЩэЕФБОЕздыЩљЕФЧАЬсЯТЃЉЃЌЭЈЙ§ЪфШыСщУєЖШдівцЃЈЛАЗХЃЉЗХДѓЪфШыаХКХДгЖјЬсЩ§аХдыБШЁЃ
дкЁИДІРэЦїЯЕСаЁЙЃЌЕчЦНБэВЩгУdBuЮЊЕЅЮЛЃЌМД0dBuЮЊДІРэЦїЕФЁАБъГЦВйзїЕчЦНЁБДѓаЁЁЃдквєдДГЃЙцВЅЗХ/ЛАЭВе§ГЃЪЙгУОрРыЕФЧщаЮЯТЃЌЙлВьВЂЛКТ§ЕїећЪфШыСщУєЖШЃЌЪЙЕУвєЦЕДІРэЦїЪфШыЭЈЕРЕчЦНБэДѓаЁДяЕНЁАБъГЦВйзїЕчЦНЁБЁЃУПвЛЪфШыЭЈЕРЖМЪЧШчДЫЩшжУЁЃДЫЪБвєЦЕДІРэЦїЕФдівцНсЙЙДІгкЫљЮНЕФЁА0Нј0ГіЁБЕФдівцНсЙЙЃЌаХКХЕчЦНгыЩшБИзюДѓЕчЦНжЎМфНЋБЃСєГфЗжЕФЗхжЕПеМфЃЈHeadroomЃЉвдТњзуКѓајгУЛЇе§ГЃЕФвєСПВйзїЗЖЮЇЁЃ
Г§СЫdBuЕчЦНБэЭтЃЌСэЭтвЛжжГЃМћЕФЗНЪНЪЧВЩгУdBFSЕчЦНБэЃЈТњПЬЖШЕчЦНБэЃЉЁЃШчЁИДІРэЦїЯЕСаЁЙЕФзюДѓЕчЦНБъЖЈЮЊ0dBFSЃЌдђ-18dBFSЮЊДІРэЦїЕФЁАБъГЦВйзїЕчЦНЁБДѓаЁЁЃЙЄГЬЪІжЛашНсКЯОпЬхИУЩшБИЕФВЮЪ§ЙцИёБэКѓОЭПЩвдЭЦЫуdBFSЕчЦНБэЩЯЦфЫћПЬЖШЯрЖдгІЕФЕчЦНжЕЁЃ
жЕЕУзЂвтЕФЪЧЃЌдівцВЛНіЛсЖдаХКХЗХДѓЃЌвВЛсЖдгыаХКХвЛЭЌНјШыЕФЩЯвЛМЖдыЩљНјааЗХДѓЁЃШчЁАвєСПЭЦзгЁБЕШОпгаЕчЦНЕїНкЙІФмЕФдівцЪЧЗЂЩњдкADCФЃЪ§зЊЛЛжЎКѓЃЌЫќЕФЩЯвЛМЖдыЩљГ§СЫАќКЌгыаХКХвЛЭЌНјШыЕФдыЩљЃЌвВАќКЌСЫЩшБИНгПкздЩэЕФБОЕздыЩљЁЃвђДЫЃЌОЁЙмЖМЪЧЖдаХКХЦ№ЕНвєСПЕїНкзїгУЃЌдкаХдыБШЬсЩ§ЗНУцЁАвєСПЭЦзгЁБВЂВЛФмДяЕНгыСщУєЖШдівцЭЌбљЕФаЇЙћЁЃЫљвдЫЕЃЌвЛЕЉСщУєЖШдівце§ШЗЩшжУЃЌОЭВЛвЫдйЦЕЗБЕїећЁЃЗёдђНЋЦфзїЮЊвєСППижЦЪжЖЮНЛИјзюжегУЛЇЃЌЛсМЋДѓГЬЖШЕигАЯьЯЕЭГЮШЖЈадЁЃ
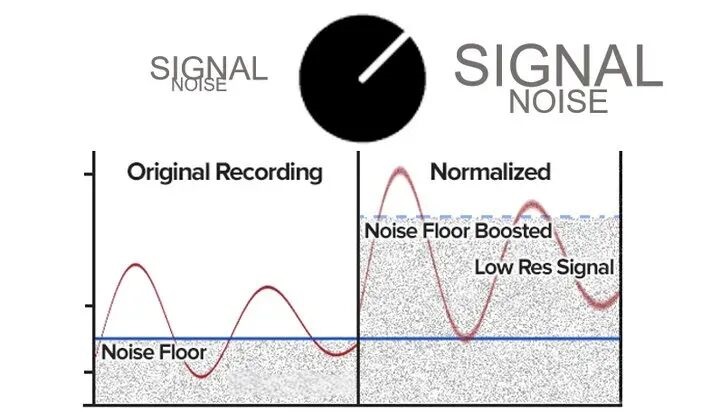
дівцВЛНіЛсЖдаХКХЗХДѓЃЌвВЛсЖдгыаХКХвЛЭЌНјШыЕФдыЩљНјааЗХДѓ
ЕНетвЛВНвєЦЕДІРэЦїЕФдівцНсЙЙЕїећНсЪјЁЃЭЌРэЃЌЭЈЙ§ЖддкаХКХСДТЗЩЯДІгкЙІЗХжЎЧАЕФЩшБИНкЕуЃЌЖМНјааЁА0Нј0ГіЁБЕФЩшжУЃЌетбљЕФдівцНсЙЙЮвУЧГЦЮЊЭГвЛдівцЃЈUnity gainЃЉЁЃгЕгаЯрЭЌЕФЗхжЕПеМфЕФКУДІЪЧФмЙЛзюДѓЛЏгУЛЇдкЪЙгУЙ§ГЬЕФвєСПЬсЩ§ЗЖЮЇЃЌВЛЛсгЩгкЁАФОЭАЖЬАхаЇгІЁБЖјЬсЧАВњЩњЯїВЈЛђНЕЕЭаХдыБШЁЃ
ЃЈ4ЃЉЩшжУЙІЗХСщУєЖШ
зюКѓвЛВНОЭЕНСЫНЋЩљвєЗХГіЕФЛЗНкЁЃДѓВПЗжЧщПіЯТЃЌЙІЗХЕФвєСПЩшжУгЩЮЛгкЙІЗХЧАУцАхЕФСщУєЖШЕїНка§ХЅЭъГЩЃЈШчЙћЪЙгУЕФЪЧDSPЙІЗХЃЌдђЭЈЙ§ЕїНкDSPЕФЪфГідівцРДЭъГЩШЮЮёЃЉЁЃдкПЊЦєЙІЗХЧАЃЌЧызЂвтНЋа§ХЅЕїНкжСЙиБезДЬЌвдЗРжЙЭЛШЛЕФДѓЕчЦНаХКХЖјЕМжТШЫЖњгРОУадЬ§ОѕЫ№ЩЫЛђбяЩљЦїМАЦфЫћЯЕЭГЩшБИЫ№ЛЕЁЃ
ЕїНкПЊЪМЪБЃЌЭЌбљНЈвщдквєдДГЃЙцВЅЗХЁЂЛАЭВе§ГЃЪЙгУОрРыЕФЧщаЮЯТЃЌВЂЛКТ§ЕїећЙІЗХа§ХЅжБЕНбяЩљЦїЕФФПБъИВИЧЧјгђДяЕНФПБъЛђБъзМРЉЩљЩљбЙМЖЁЃУПвЛзщЙІЗХбяЩљЦїЖМЪЧШчДЫЩшжУЁЃжСДЫЃЌЯЕЭГЕФдівцНсЙЙОЭЭъГЩСЫПьЫйЕїНкЁЃ

ЩљбЇЗТецШэМўЖдЯЕЭГЩљбЙМЖИВИЧНјааЩшМЦ
ЕїЪдЭъЛЙгаЕздыЃППЩФмЪЧетаЉдвђ
гаЪБФуЛсдкРЉЩљЯЕЭГЕБжаЗЂЯжЃЌдквбОЭъГЩдівцНсЙЙЩшжУжЎКѓЃЌШдШЛГіЯжНЯДѓЕФБОЕздыЩљЁЃ
ЕквЛжжПЩФмЪЧЩшМЦЕФЩљбЙМЖИпгкЛЗОГЪЕМЪЪЙгУашЧѓЃЌЭЈЙ§НЕЕЭЙІЗХЪфГіСщУєЖШПЩвдОіЖЈзюжеКЯЪЪЕФвєСПЁЃ
ЕкЖўжжПЩФмЪЧВЛЕУВЛбЁдёелжаЕФЗНАИЃЌЮоТлЪЧЦРЙРдыЩљЪЧРДздгкЯЕЭГжаФФвЛИізюБЁШѕЕФЛЗНкЃЌВЂХаЖЯЪЧЗёвЊЖдЦфНјааЬцЛЛЃЛЛђЪЧЭЈЙ§бЙЫѕЗхжЕПеМфВЂЯожЦгУЛЇвєСПЕїНкЗЖЮЇЕШЪжЖЮЃЌЪЙЕУаХКХФмЙЛОЁСПдЖРыБОЕздыЩљЁЃ
ЕкШ§жжПЩФмЪЧбяЩљЦїЙІТЪЪ§СПЩйЃЌЙІТЪаЁЃЌЮоЗЈТњзуЪЙгУашЧѓЪБвЛЮЖдіМгЙІЗХЗХДѓБЖЪ§ЃЌДгЖјЕМжТБОЕздыЩљЭЌбљЗХДѓЃЌдкУЛгаРЉЩљЬѕМўЯТгаПЩЮХЕФЩшБИЕздыЩљЃЌетЪБашвЊжиаТЩшМЦЛђдіМгбяЩљЦїЪ§СПЁЂЙІТЪРДНтОіИУЮЪЬтЁЃ
СэЭтЃЌОЁЙмВЛЪЧБОЮФЕФжиЕуЃЌашвЊЧПЕїЕФЪЧЃКдкРЉЩљЯЕЭГЕїЪджаЃЌдівцНсЙЙЕїећНіНіжЛЪЧЦфжавЛВНЁЃМДЪЙдівцНсЙЙЩшжУЭъГЩЃЌШдШЛЛсГіЯжвєСПЕїНкЗЖЮЇГЃвђЩљЗДРЁЃЈаЅНаЃЉЖјЪмЯоЃЌЛђЪЧЮоЗЈЪЕЯжЖржЛЛАЭВЭЌЪБДђПЊЕФЧщПіЁЃ
ДЫЪББиаывЊвтЪЖЕНЃЌЮвУЧжЛгаЯШЭЈЙ§КЯРэЕФвєЦЕЯЕЭГЩшМЦЁЂЩљбЇПМТЧЁЂвєЦЕЩшБИбЁаЭЁЂвдМАЭЈЙ§дЫгУвєЦЕДІРэЦїЛьвєЫуЗЈЛђепMix-minusЗНЪНЕШЃЌШчЙћвЛЮЖЕФЪЙгУЗДРЁвжжЦЦїЕШРДНтОіЩљЗДРЁЮЪЬтЃЌжЛФмНЋЯЕЭГЛђвєЦЕжЪСПБфЕФдНРДдНдуИтЃЌВЂВЛЛсгаЯджјЕФДЋЪфдівцЬсЩ§ЁЃ
ЫљвдЃЌзїЮЊзЈвЕЕФвєЦЕШЫЪПЃЌвЛЖЈЪЧзЈзЂзЈвЕвєЦЕЩшМЦЁЂбЁаЭЁЂКЯРэЪЙгУDSPЫуЗЈКЭЗНЗЈММЧЩЃЌВХФмЪЕЯжНЋвЛИіКУЕФвєЦЕЯЕЭГГЪНЛИјзюжегУЛЇЁЃ

 МђРњЭЖЕн
МђРњЭЖЕн ЩЬЮёКЯзї
ЩЬЮёКЯзї УНЬхДЙбЏ
УНЬхДЙбЏ ЮЂаХЖўЮЌТы
ЮЂаХЖўЮЌТы

